Quantitative sensitivity analysis¶
When analyzing (complex) computational models it is often unclear from the model specification alone how the inputs of the model contribute to the outputs. As we’ve seen in the previous tutorial on Qualitative sensitivity analysis, a first step is to sort the inputs by their respective order of importance on the outputs. In many cases however, we would like to learn by how much the individual inputs contribute to the output in relation to the other inputs. This can be done using Sobol indices ([13]). Classical Sobol indices are designed to work on models with independent input variables. However, since in economics this independence assumption would be very questionable, we focus on so called generalized Sobol indices, as those proposed by [8], that also work in the case of dependent inputs.
Generalized Sobol indices¶
Say we have a model \(\mathcal{M}:\mathbb{R}^n \to \mathbb{R}, x \mapsto \mathcal{M}(x)\) and we are interested in analyzing the variance of its output on a given subset \(U \subset \mathbb{R}^n\), i.e. we want to analyze
where \(\mu_U := \int_U \mathcal{M}(x) f_X(x) \mathrm{d}x\) denotes the restricted mean of the model and \(f_X\) denotes the probability density function imposed on the input parameters. For the sake of brevity let us assume that \(\mathcal{M}\) is already restricted so that we can drop the dependence on \(S\). To analyze the effect of a single variable, or more general a subset of variable, consider partitioning the model inputs as \((y, z) = x\). The construction of Sobol and generalized Sobol indices starts with noticing that we can decompose the overall variance as
which implies that
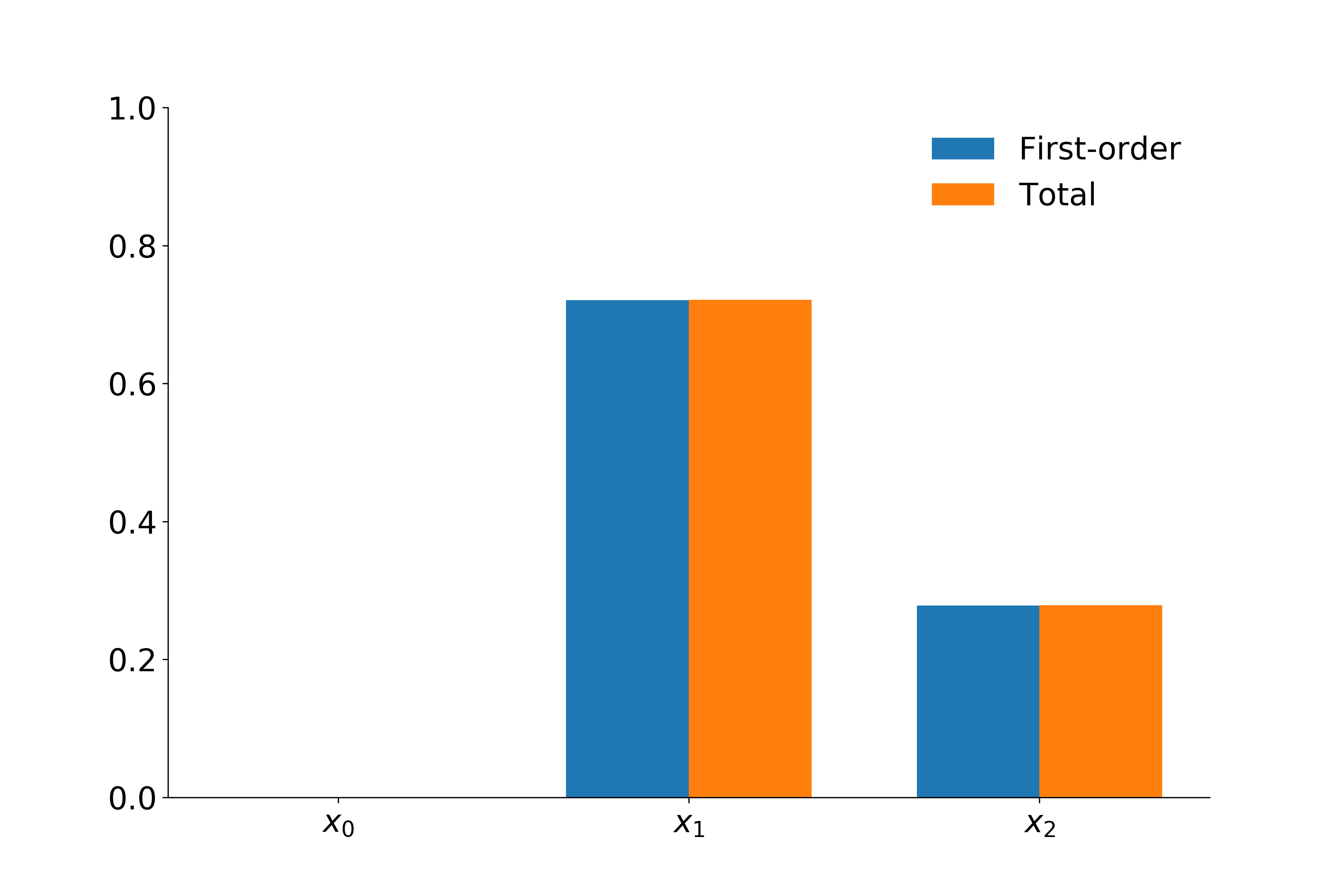
We call \(S_y\) the first order effect index of the subset \(y\) and we call \(S_z^T\) the total effect of the subset \(z\). Notice that for each partition of the input space \(y\) and \(z\), the above provides a way of computing the fraction of explained variance. For the sake of clarity, assume \(y\) represent only a single input variable. Then \(S_y\) can be interpreted as the effect of \(y\) on the variability of \(\mathcal{M}\) without considering any interaction effects with other variables. While \(S_y^T\) can be thought of as representing the effect of \(y\) on the variance via itself and all other input variables.
Again, we now apply this to the EOQ model. Given the current limits to our implementation and the fact that the parameters of the model need to remain positive, we specify that the parameters follow a normal distribution with a very small variance.
Shapely values¶
In this overview, we give brief notational insights on variance-based sensitivity analysis as well as the Shapley value’s theoratical framework ([14]). We follow the framework on variance-based sensitivity analysis and Shapley values developed by [14].
Variance-based Sensitivity Analysis (SA) can be illustrated in the following manner. Consider a model with \(k\) inputs denoted by \(X_K = \{X_1, X_2, X_3, \dots, X_k\}\) where \(K = \{1, 2, \dots, k\}\). Consider also \(X_J\), which indicates the vector of inputs included in the index set \(J \subseteq X\). The uncertainty in \(X_K\) is represented by the joint cumulative distribution \(G_K\). Furthermore, we denote the joint distribution of inputs included in the index set \(J\) as \(G_J\) and the marginal distribution of each \(X_i\) as \(G_i\). The model is treated as a blackbox, and only the model response is analysed. The model response \(Y\) is a function of the inputs, i.e., \(Y = f(X_K)\) and therefore \(f(X_K)\) is stochastic due to the uncertainty in \(X_K\) although \(f(\cdot)\) is deterministic. Often, \(f(\cdot)\) has a complex structure, and does not have a closed form expression. The overall uncertainty in the model output \(Y\) caused by \(X_K\) is \(Var[Y]\), where the variance is calculated with respect to the joint distribution \(G_K\). The Shapley value then, helps us to quantify how much of \(Var[Y]\) can be attributed to each each \(X_i\).
An analogous framework to the one developed for variance-based sensitivity analysis above is apparent in the specification of the Shapley value. Formally, a k-player game with the set of players \(K = \{1,2, \dots, k\}\) is defined as a real valued function that maps a subset of \(K\) to its corresponding cost (or value), i.e., \(c: 2^K \rightarrow {\rm I\!R}\) with \(c(\emptyset) = 0\). With this in mind, \(c(J)\) then, represents the cost that arises when the players in the subset \(J\) of \(K\) participate in the game. The Shapley value for player \(i\) with respect to \(c(\cdot)\) is defined as
where \(|J|\) indicates the size of \(J\). In other words, \(v_i\) is the incremental cost of including player \(i\) in set \(J\) averaged over all sets \(J \subseteq K \backslash \{i\}\). The Shapley value gives equal weight to each \(k\) subset sizes and equal weights amongst the subsets of the same size, which is important in determining the fairness of the variance allocation in the calculation of Shapley effects in variance-based sensitivity analysis ([14]). Reconciling the two frameworks by direct comparison, we can think of the set of \(K\) players as the set of inputs of \(f(\cdot)\) and define \(c(\cdot)\) so that for \(J \subseteq K\), \(c(J)\) measures the variance of \(c(J)\) caused by the uncertainty of the inputs in \(J\).
The ideal \(c(\cdot)\) should satisfy the conditions: \(c(\emptyset) = 0\) and \(c(K) = Var[Y]\). Two such candidates for such \(c(\cdot)\) can be considered, and have been shown to be equivalent are equivalent ([14]). The first cost function is
This cost function satisfies the two conditions from above and was originally put forth by [12] and later adopted by [14] in their paper. The cost function can be rewritten as \(\tilde{c}(J) = Var[Y] - E[Var[Y|X_J]]\), and interpreted as the expected reduction in the output variance when the values of \(X_J\) are known. The second cost function that satisfies the required conditions is
where \(X_{-J} = X_{K \backslash J}\). \(c(J)\) is interpreted as the expected remaining variance in \(Y\) when the values of \(X_{-J}\) are known. In this case, the incremental cost \(c(J \cup \{i\}) -c(J)\) can be interpreted as the expected decrease in the variance of \(Y\) conditional on the known input values of \(X_i\) out of all the unknown inputs in \(J \cup \{i\}\).
Although both cost functions result in the same Shapley values, their resultant estimators from Monte Carlo simulation are different. [15] reveal that the Monte Carlo estimator that results from the simulation of \(\tilde{c}(J)\) can be severely biased if the inner level sample size used to estimate the conditional expectation is not large enough. Given the already computationally demanding structure of microeconomic models, this added computational complexity is costly. In contrast however, the estimator of \(c(J)\) is unbiased for all sample sizes. Because of this added feature, we follow [14] in using the cost function \(c(J)\) rather that \(\tilde{c}(J)\). We therefore define the Shapley effect of the \(i_{th}\) input, \(Sh_i\), as the Shapley value obtained by applying the cost function \(c(J)\) to the Shapley value equation. Indeed, any Shapley value defined by the satisfaction of the two conditions: \(c(\emptyset) = 0\) and \(c(K) = Var[Y]\) imply that
even if there is dependence or structural interactions amongst the elements in \(X_K\). Throughout the package, we use \(Sh_i\) to denote the Shapley effect and \(v_i\) to denote the generic Shapley value.